[논문 리뷰 #3] 긴 문서를 위한 BERT 기반의 End-to-End 한국어 상호참조 해결
긴 문서를 위한 BERT 기반의 End-to-End 한국어 상호참조해결
: 조경빈, 정영준, 이창기 (강원대학교 빅데이터메디컬융합학과), 류지희, 임준호 (한국전자통신 연구원)
(제 33회 한글 및 한국어 정보처리 학술대회 논문집(2021년))

00. 서론
최근 한국어 상호참조해결 연구에서는 BERT를 이용해 단어의 문맥 표현을 얻어 성능을 향상시켰다. 하지만 512토큰 이상의 긴 문서를 처리하기 위해서는 512이 토큰 이하로 문서를 분할하여 처리하기 때문에 길이가 긴 문서에 대해서는 상호참조해결 성능이 낮아지는 문제가 있다. 이 논문에서는 512토큰 이상의 긴 문서를 위한 BERT기반 End-to-End 상호참조해결 모델을 제안한다.
01. 상호참조해결

상호참조해결이란 동일한 개체(entitiy)를 의미하는 모든 멘션(mention)을 찾아 그룹화(Clustering) 하는 자연언어처리 태스크이다. 멘션은 명사, 대명사, 명사구, 스팬(Span) 등 상호참조 해결의 대상이 되는 것을 의미하며 중심어를 중심으로 이를 수식하는 수식어를 포함한다. 개체는 동일한 멘션의 집합으로 상호참조의 결과가 된다. 스팬이란 한개 이상의 단어로 이루어진 명사구가 될 수 있는 단어 집합을 말한다.
홍길동은 ㅇㅇ병원의 의사이다. 그의 환자 가나다는 곧 퇴원을 앞두고 있다.
홍길동과 그의 제자들은 가나다의 생일을 맞아 그의 병실에 방문한다.
같은 색으로 표현 된것이 상호참조해결이 된 개체들이다. 다른 글자로 표현되어있지만 같은 대상을 가르키고 있는것을 알 수 있다.
02. 관련연구

최근 한국어 상호참조해결 연구는 포인터 네트워크를 사용하는 모델과 멘션 탐지 태스크와 상호참조 해결태스크를 동시에 진행하는 end-to-end 모델이 연구 되었다. 포인터 네트워크를 사용한 연구는 RNN을 기반으로 문맥정보를 인코딩하여 포인터 네트워크를 사용하거나 ELMo와 CNN을 적용한 포인터 네트워크를 사용한 방법이 연구되었다.
End-to-End 모델 연구는 멘션 탐지 태스크와 상호참조해결 태스크를 동시에 해결하며, 가능한 모든 스팬을 멘션 후보로 간주하여 문제를 해결한다. (김기훈 외)의 논문은 기존 End-to-End 모델에 문장 수준에서만 상호참조가 되는 일관성 문제(Consistency errors)를 해결하기 위해 고차 추론(high-order)를 적용하고, 고차 추론의 복잡도를 줄이기 위해 coarse-to-fine을 적용하였다. (Mandar et al)의 논문은 End-to-End 모델에 BERT를 추가해 영어 상호참조해결에서 많은 성능 향상을 보였으며, 토큰의 개수가 512이상인 문서를 BERT에 입력하기 위해 문서를 정해진 길이의 세그먼트 단이로 나누어 하나의 배치로 병렬로 수행하여 길이가 긴 문서에 대해 성능 향상을 보였다.

(김기훈 외)의 논문은 (Mandar et al)의 모델에 개체명 자질과 의존구문 분석 자질을 적용에 한국어의 특성을 반영시켰다. 양방향 LSTM 레이어를 추가해 BERT 표현과 문맥정보에 대한 hidden state를 만들어 한국어 상호참조해결을 수행한다. 하나의 문서를 512크기의 세그먼트 단위로 나누어 하나의 배치로 병렬로 수행하여 문맥표현을 얻은 후 이를 다시 연결하여 양방향 LSTM의 입력으로 주어 전체 문맥정보를 모델링 한다.
03. 제안 모델

end-to-end 상호참조해결 모델은 선행사와 맨션 쌍이 상호참조될 조건부 확률 분포를 학습하는 것이 목표이다. 모델은 두 단계를 거쳐 문제를 해결한다.
- 스팬 표현(span representations)과 멘션 스코어를 통해 멘션 후보($k$개)들을 결정하는 단계
- 추출된 멘션 후보들과 선행사 후보($c$개)간의 상호참조해결을 결정하는 단계
$k,c$는 하이퍼 파라미터로 조절 가능한 값이다.
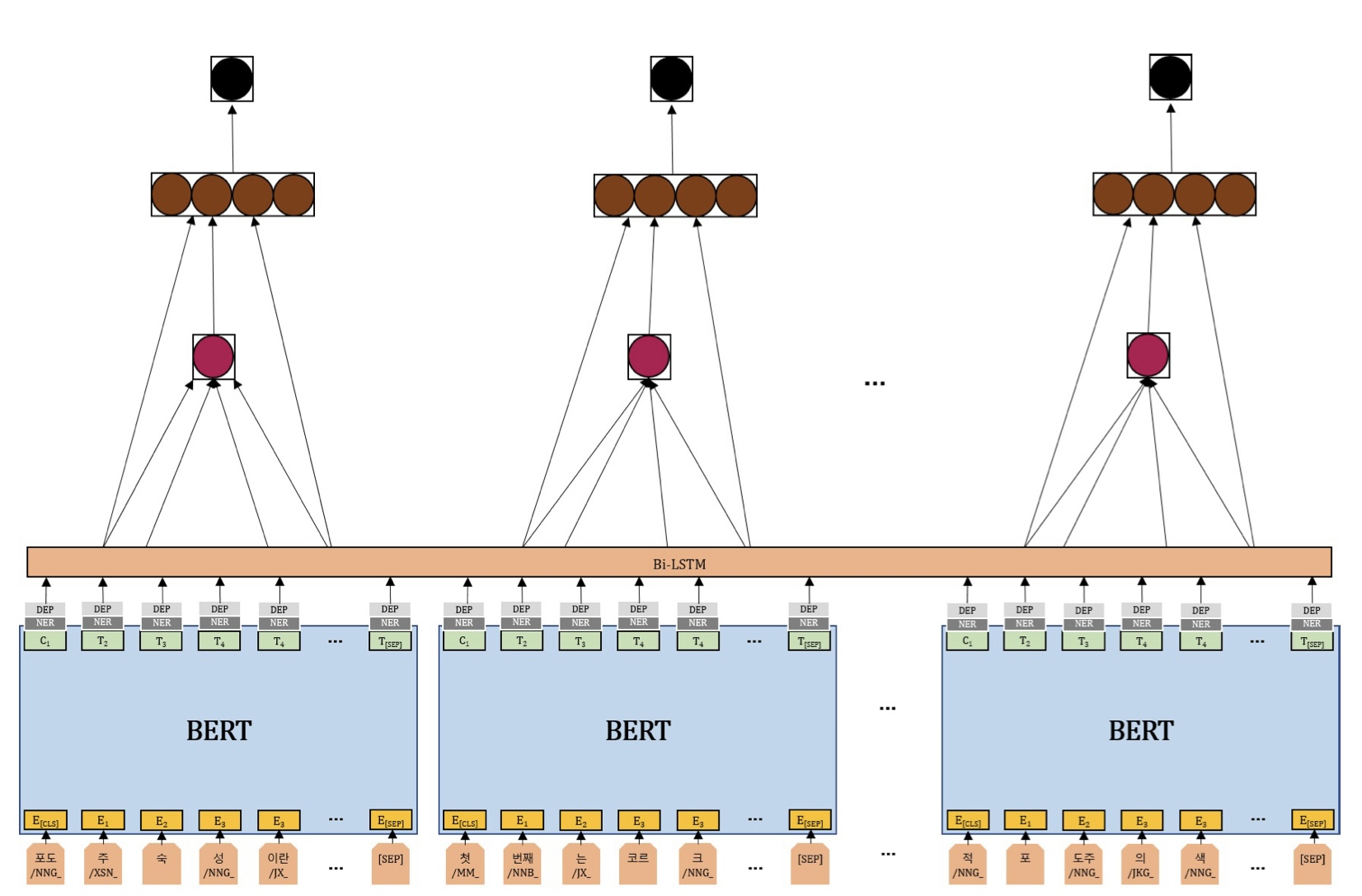
기존의 Bi-LSTM을 추가한 모델은 BERT를 이용해 단어의 문맥 표현, 즉 임베딩을 얻고 한국어 특성 반영을 위해 개체명 자질과 의존구문 분석 자질(회색)을 추가하여 Bi-LSTM층(주황색)을 통과해 단어의 최종 문맥 표현을 얻었다.

논문에서 제안하는 긴 문서를 위한 상호참조해결 모델은 긴 문서를 512 이하의 토큰으로 쪼개어 기존의 Local BERT에서 로컬 어텐션(local attention)정보를 이용하여 단어의 1차 문맥표현을 얻는다. 이들을 다시 연결(Concatenation)해 쪼개기 전의 긴 문서의 글로벌 포지셔널 인코딩(Global Positional Encoding) 또는 임베딩(Embedding)값을 더한다. 이 값을 Global BERT의 입력으로 주어 얻은 글로벌 어텐션(global attention)정보를 이용해 단어의 최종 문맥표현을 얻는다.

1. 스팬표현과 맨션 스코어를 얻는 단계
형태소 단위에 BPE가 적용된 입력열 토큰 $X$를 512이하의 토큰으로 쪼갠 후 기존의 Local BERT에 입력으로 주어 $BERT(X_t)$를 얻는다. 쪼개기 전의 긴 문서의 글로벌 포지셔널 인코딩 또는 임베딩인 $G$_$PE$를 element wise sum(벡터 요소 간의 합)을 수행하여 $z_t$를 계산한다. 구해진 $z_t$를 Global BERT에 입력으로 주어 $G$_$BERT(z_t)$를 얻은 후, 개체명 자질(ner), 의존 구문 분석 자질(dep)과 연결한 벡터 $v_t$를 GLU(Gated Linear Unit)의 입력으로 주어 $h_t$를 구한다. $h_t$는 스팬 표현 $g_i$를 만들기 위해 사용된다.

스팬 $span_i$의 시작과 끝은 $START(i)$와 $END(i)$로 표현한다. 위의 식 1-3은 스팬의 중심어표현 $\hat{h}_t$를 구하는 과정이며 $span_i$의 모든 토큰들에 대한 가중치 합을 수행한 값이다. 가중치 $a_t$는 FFNN(Feed-Forward Neural Network)으로 계산된다. 스팬의 시작 $h_{START(i)}$, 스팬의 끝 $h_{END(i)}$, 스팬 중심표현 $\hat{h}_t$, 자질벡터 $\phi(i)$를 연결하여 스팬표현 $g_t$를 얻는다.계산된 스팬 표현$g_t$는 멘션 스코어 $s_m(i)$를 구하는데 사용되며, 멘션 스코어 기준 상위 $k$개를 멘션 후보로 정한다.

2. 상호참조해결 스코어와 고차 추론
구해진 $k$개의 멘션 후보들로, 선행사 여부를 판별하는 선행사 스코어 $s_c$, $s_a$와 최종적으로 상호참조 여부를 결정하는 상호참조해결 스코어 $s(i,j)$ 를 구한다. $i$는 현재 맨션의 인덱스, $j$(1\leq j\leq i-1)은 선행사의 인덱스이다. $g_i$와 $g_j$는 $i$와 $j$멘션의 스팬표현을 나타낸다. 선행사 스코어 $s_a(i,j)$와 $s_c(i,j)$는 $g_i$와 $g_j$의 선행사 인지 여부를 나타내는 스코어이다.
$s_a(i,j)$는 멘션, 선행사 각각의 스팬 표현과 element wise의 결과인 $g_i\bigcirc g_j$, 두 스팬의 거리 자질인 $\phi(i,j)$를 연결하여 FFNN을 수행한다. 이 과정의 시간 복잡도는 $O(n^3)$이며, 계산 비용을 줄이기 위해 bilinear 연산인 $s_c(i,j)$를 도입한다. coarse-to-fine을 진행한 후, 상위 $c$개에 대하여 $s_a(i,j)$ 선행사 스코어를 계산한다. 마지막으로, 멘션 스코어와 선행사 스코어를 합하여 상호참조해결 스코어를 계산한다.
문장 수준에서는 상호참조해결이 되는 것처럼 보이지만, 전체 문서로 보았을때 상호참조해결이 안되는 일관성 문제를 해결하기위해 고차 추론을 적용한다.

$n$번 고차 추론을 반복 하며, 현재 멘션의 선행사들에 대한 얼라인먼트 스코어 ${a^n}_i$와 현재 멘션 정보에 대한 게이트 벡터 ${f^n}_i$를 사용하여 스팬 표현을 업데이트 해준다. 모델의 출력은 상호참조해결 스코어가 가장 높은 $k$개의 (멘션, 선행사)쌍이다.

04. 실험 및 결과

제안한 길이가 긴 문서를 위한 상호참조해결 모델을 실험하기 위해 평균 문서길이가 긴 ETRI WIKI 도메인 상호참조해결 데이터셋을 이용한다. 데이터 셋의 평균 문서길이는 26문장, 1704음절이다. 데이터 셋은 학습 데이터(train) 891문서, 개발 데이터(dev) 50, 평가 데이터(test) 50 문서로 구성한다.
제안한 모델의 Local BERT는 ETRI의 KorBERT(BERT-base)를 사용 했다.

상호참조해결의 성능 측정을 위해 중심어 경계(head boundary)를 기준으로 $MUC, B^3, CEAF-e, CoNLL F1$을 사용한다.
제안한 모델의 Global BERT layer의 효과를 검증하기위한 실험을 진행한다. 표 1은 Local BERT의 레이어를 12로 고정하고, Global BERT의 레이어 수를 변경한 모델의 결과값을 나타낸다. 레이어를 추가 할 수록 성능이 하락하여 1개의 레이어를 이용했을 때 성능이 가장 좋은 것을 확인할 수 있다.
표 2는 Local BERT 레이어와 Global BERT 레이어 수에 따른 모델의 성능 비교 결과이다. Local BERT의 레이어수가 11개 일때 가장 좋은 성능을 보이는 것을 알 수 있다.

다음은 제안 모델의 Global Positional Encoding/Embedding의 효과를 검증하기 위한 실험이다. 모델의 $G$_$PE$ 부분을 교체하면서 실험을 진행하며, Local BERT 레이어 11개, Global BERT 레이어 1개를 사용한다. 트랜스포머 모델에서 사용한 Positional Encoding과 동일한 식을 사용하여 긴 문서의 Global Positional Encoding 값을 계산한다. 긴 문서의 토큰 수를 고려하여 Positional Embedding의 크기를 4096으로 고정하며, Positional Embedding의 초기값을 3가지 방법으로 초기화하여 실험한다. 실험 결과, KorBERT의 Positional Embedding을 8번 반복해서 연결하여 초기화 한 경우가 가장 높은 성능을 보인다.
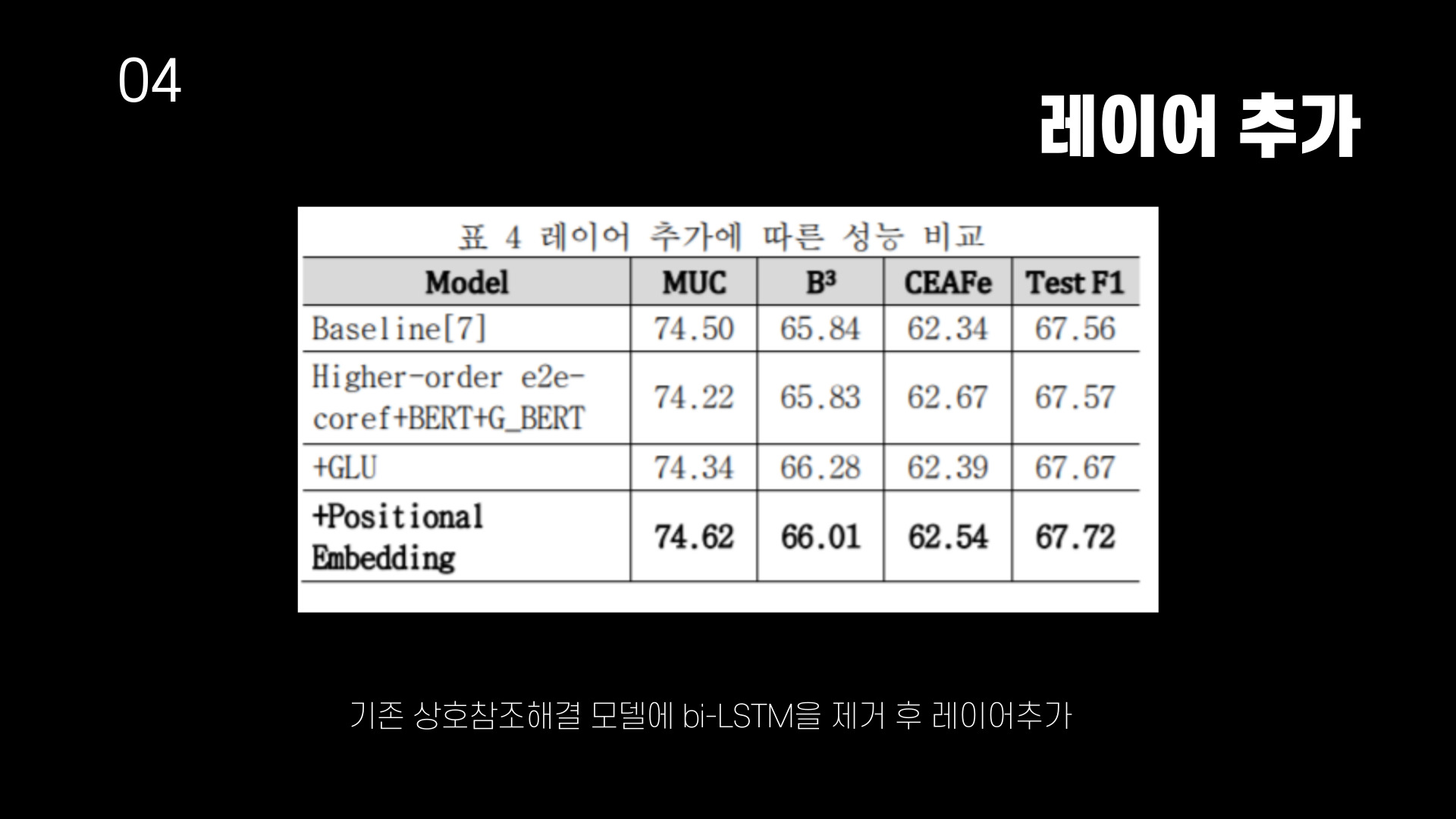
기존 BERT 기반의 end-to-end 상호참조해결 모델(Baseline)에 bi-LSTM을 제거하고 순차적으로 G_BERT, GLU, Positional Embedding을 추가한 성능을 비교한 것이다. 최종적으로 기존 모델에 비해 성능이 0.16% 향상되었다.

기존 모델에 비해서 제안 모델이 메모리 사용량과 속도 면에서 우수하다는 것을 보여주는 표이다. 전체 문서의 정보를 통합하기 위해 사용했던 bi-LSTM 대신에 셀프어텐션(self-attention)(Global BERT layer)를 사용하여 GPU 메모리 사용량을 줄이고 GPU의 병렬성을 활용하여 속도를 향상시킨 것으로 생각한다.

가시성을 위해 인물에 대한 멘션을 표기한 예제이다. 제안한 모델은 "에릭"과 왕자를 같은 엔티티로 묶었지만 기준 모델의 경우 서로 다른 것으로 구분하는 것을 볼 수 있다. 실제로는 같은 것을 지칭하지만 기준 모델의 첫 번째 문장에서 "그에게"가 "에릭"이 아닌 왕자만을 가리키는 문자가 발생하고 있다. 이 문제는 세그먼트 사이의 Global한 정보를 제대로 인코딩하지 못했기 때문으로 보인다.
05. 끝
BERT가 512 보다 긴 문서를 처리하지 못하는 점을 보완하기 위한 방법을 제안한 논문이다. Global BERT를 이용하여 분할한 문서를 전체적으로 다시 보정하면서 문서의 처음과 끝에서 나오는 상호참조해결을 잘 해결한 것같다. 성능향상을 보임과 동시에 메모리 사용량을 감소시키며, 속도는 향상시키는 점이 와닿는다. 레이어를 추가하거나 연산을 추가함으로 성능을 향상시킬 수는 있으나 속도 및 메모리 사용량은 비효율 적이게 되는데 그것을 보완한 점을 잘 보고 배워야 겠다.