마스크 언어 모델 기반 비병렬 한국어 텍스트 스타일 변환 : 배장성, 이창기, 황정인, 노형종(강원대학교 컴퓨터 과학과, 엔씨소프트 NLP Center Language AI Lab)
(제 33회 한글 및 한국어 정보처리 학술대회 논문집(2021년))

00.서론
텍스트 스타일 변환은 기계학습모델을 이용해 해결 할 수 있지만 인공지능에서 항상 문제가 되듯 이 문제 또한 대량의 병렬 말뭉치를 필요로 한다. 각 스타일에 대응되는 병렬 말뭉치는 구하기 힘들 뿐더러 구축하는데도 많은 비용과 시간이 필요하다. 따라서 최근에는 비병렬 말뭉치를 이용해 텍스트 스타일 변환을 수행할 수 있도록 하는 많은 연구들이 이뤄지고 있다. 이 논문에서는 입력 텍스트의 내용을 유지하면서 삭제된 스타일 토큰을 원하는 스타일의 토큰으로 변경하기 위해 삭제된 토큰을 마스크 언어모델을 이용해 생성하는 방법을 통해 스타일 변환 문제를 해결하고자 한다.
01. 텍스트 스타일 변환

텍스트 스타일 변환(text style transfer)는 입력 스타일(source style)로 쓰여진 텍스트의 내용을 유지하며 목적 스타일(target style)의 텍스트로 변환하는 문제이다. 가장 기본적인 예시로 긍정문으로 쓰여진 문장을 부정적인 문장으로 바꾸는 것, 구어체를 문어체로 바꾸는 것 등이 있을 수 있겠다. 비병렬 말뭉치를 이용한 텍스트 스타일 변환 연구는 적대적 학습을 통해 입력된 텍스트 에서 내용과 스타일을 분리한 후 디코더를 이용해 변환된 문장을 생성하는 방법과, 입력된 문장에서 스타엘에 해당하는 토큰을 찾은뒤 삭제한 후 이를 목적스타일의 단어로 대체하거나 생성하는 방법이 있다.

스타일 토큰을 삭제한 문장과 스타일 속성을 표시하는 값을 생성모델의 입력으로 사용하는 기존 연구는 스타일 변환을 생성모델을 통해 해결 하기 때문에 생성과정에서 문제점이 발생할 수 있다. 원래 문장이 가지고 있는 내용이 누락이 되거나 다른 내용의 문장이 생성 되는 문제가 발생하는 것이다. 또한 스타일과 내용을 각가 학습해야 하기 때문에 학습이 더 어려워진다는 문제가 있다.
02. 한국어 텍스트 스타일 변환 모델

이 논문에서 제안하는 모델은 두가지이다. 하나는 입력 문장에서 분류기를 이용해 스타일 토큰을 삭제하고, 삭제된 토큰을 conditional BERT를 이용해 생성하는 방법이고, 다른 하나는 사전 학습된 두개의 언어 모델을 이용해 토큰을 삭제하고, 삭제된 토큰을 Padded Masked Lanuage mopdel을 이용해 생성하는 방법이다.
03. conditinal BERT
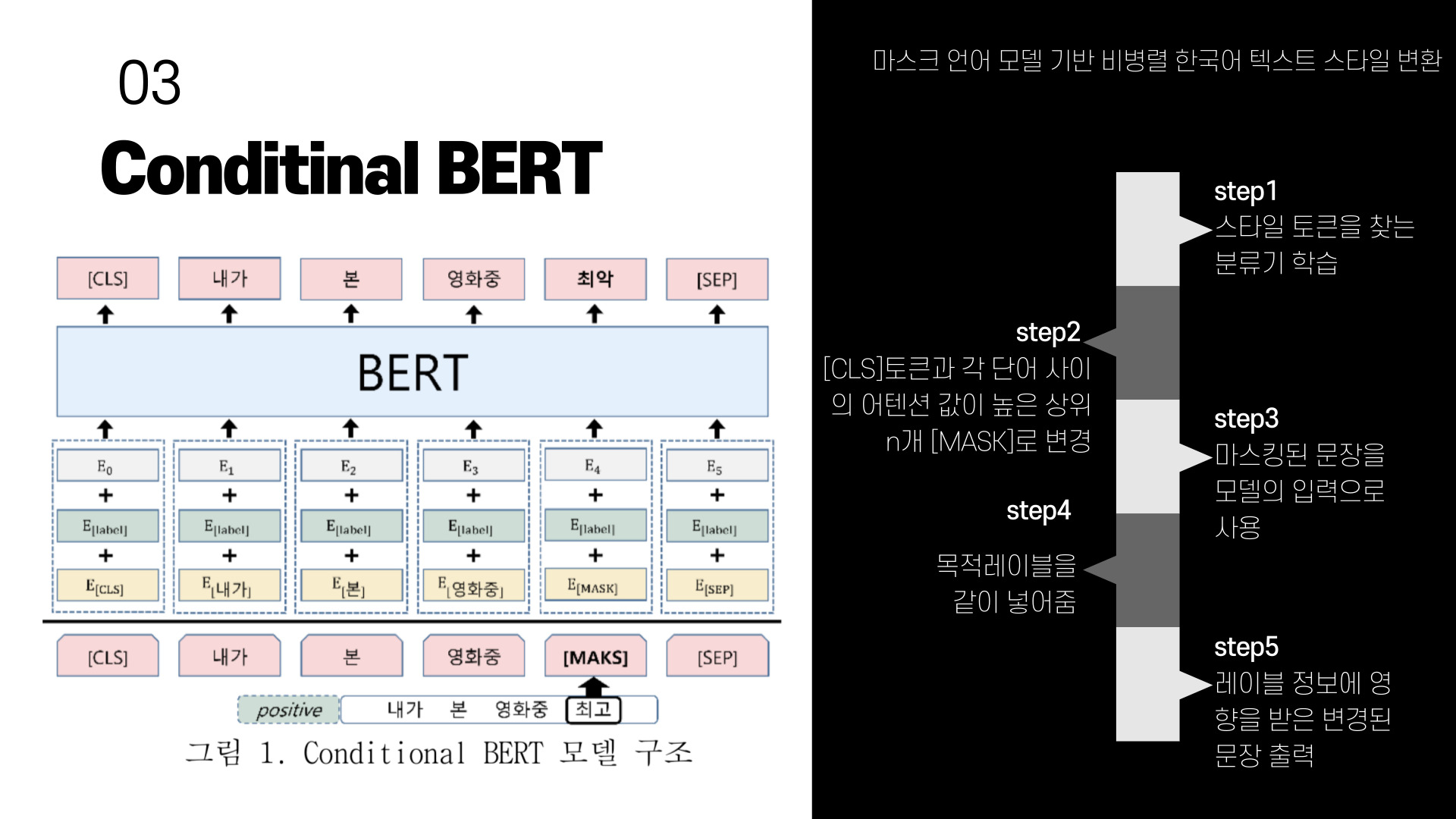
기존 BERT모델에서 마스크된 단어를 생성할 때, 생성되는 단어가 입력된 레이블 정보에 영향을 받도록 설계된 모델이다. 기존의 버트 임베딩이 [Token embedding + Segment embedding + position embedding]이였다면 condititonal 버트 임베딩은 [Token embedding + label embedding + position embedding]으로 표현된다. 모델의 학습은 사전학습된 BERT모델을 레이블의 정보와 스타일 변환에 사용할 도메인 테이터로 미세조정하는 방법을 통해 학습한다.
학습이 끝난 스타일 변환기는 가장 먼저 입력텍스트에서 스타일을 지닌 토큰을 찾기위해 소스 스타일과 목적 스타일로 구분 할 수 있는 분류기를 학습한다. "내가 본 영화중 최고" 라는 예시 문장을 보면 "최고" 토큰을 찾는 분류기를 말한다. 분류기는 각 도메인(감성분석 : 긍정-부정, 문체변환 : 채팅체-문어체)에 대해 따로 학습하며, 사전학습된 BERT 모델을 미세조정하여 사용한다. 미세조정이 완료된BERT 모델에 스타일을 변환할 입력문장을 넣고 문장에서 [CLS]토큰과 각 단어 사이의 어텐션 값이 높은 상위 N개의 토큰을 마스크로 변경한다. 마스킹된 문장을 모델의 입력으로 사용하고, 이때 목적 레이블을 같이 입력으로 넣어주면 스타일이 변경된 문장이 출력되게 된다. 이 모델은 마스킹된 토큰을 생성할때 문맥에만 의존하는 기존 BERT모델과 달리 레이블 정보에 영향을 받게된다.
그림의 예문을 보면 긍정문장이였던 "내가 본 영화중 최고" 입력문장이 부정으로 스타일이 변환된 "내가 본 영화중 최악"으로 출력되는 것을 볼 수 있다.
04. Padded Masked LM

두번째 모델인 Padded Masked LM은 N개의 마스크된 토큰을 N개의 토큰으로 생성하는 기존 BERT모델과 달리 가변길이의 토큰을 생성할 수 있는 모델이다. Padded MLM을 학습하기 위해 입력 문장에 고정된 np개의 마스크를 씌운다. i:j개의 토큰을 정답으로, j+1:i+np-1개의 토큰을 [PAD]토큰으로 학습하게 된다. 앞서 설명한 모델과 달리 스타일 토큰을 삭제하기 위한 분류기는 사용하지 않았으며, 입력스타일과 목적스타일 도메인에 대해 각각 Padded MLM을 학습한 후 실제 입력 문장에 마스크 토큰을 씌우는 방식을 사용한다. 입력 및 목적 Padded MLM에서 단어 등장 확률의 차이를 구하고, 그 차이가 가장 큰 단어를 새로운 단어로 생성하는 방법을 사용한다. targetWij는 목적 Padded MLM으로 생성한 단어를 나타내고, Wij는 실제 입력된 단어를 나타낸다. 최종 스코어는 타겟스코어와 소스 스코어를 합하여 나타내다.
05. 실험결과

한국어 긍정-부정 데이터로 네이버 영화 리뷰데이터를 사용하였다. 위의 표는 각 모델이 긍정-부정 변환을 수행한 결과이다. 전체 예제에서 '따듯한', '쓰레기', '최악의'와 같이 주로 감성분석 도메인에서 극성을 나타내는 단어를 변경하는 것을 확인 할 수 있따. 1-4번 예제는 스타일 변환이 잘 수행된 결과를 나타내며, 5번은 Padded MLM이, 6번은 Conditional BERT가, 7번은 두 모델 모다가 스타일 변환에 실패한 예제들이다. 4번 예제를 통해 Padded MLM모델이 가변 길이 생성을 통해 Conditional BERT모델 보다 더 풍부하게 단어를 생성할 수 있음을 알 수 있다.

채팅체-문어체 비병렬 변환에는 직접 수집한 데이터를 사용하였다. 문어체는 뉴스 기사로 가정하여 네이버 뉴스기사를 크롤링한 약 50만 문장을 사용하였고 채팅체는 게임 게시판에 게시된 글로 가정하여 엔씨소프트 리니지2M게시판에서 크롤링한 약 50만 문장을 사용하였다. 1번 예제는 채팅체에서 사용된 이모티콘이 마침표로 변환되어 출력된 것을 잘 보여준다. 2번 예제의 경우 Padded MLM은 완벽하게 변환을 성공하였고, Conditional BERT는 '알려주십시오.'로 변환하였지만, 입력 문장의 내용을 유지하고 있음을 보여준다. 3번 예제에서 Padded MLM이 생성한 문장을 보면 문어체로 가정한 뉴스 도메인에서 사용하는 문장을 그대로 가져 온 것을 볼 수 있다. 6번 예제에서 Conditional BERT 모델이 '혈맹.'을 '부족'으로 변환하였는데 단어 수준에서는 도메인의 내용을 잘 변경한 것으로 보이지만 원래의 내용을 보존하기 위해 마스킹에 제한을 두어 문어체로의 변환은 이루어지지 않을 것을 보여준다.
실험결과 긍부정 변환에서는 주로 극성을 띈 단어들을 변경하고, 문체 변환에서는 문장 뒤쪽의 단어들을 변환한것을 확인 할 수 있다.
06. 끝
스타일 변환이라는 주제에 관심을 가지게 해준 논문이다. 문체 변환기를 사용해서 표준어-사투리 변환기 같은 것도 만들 수 있을 것 같고.. 만약 높은 성능을 보이는 모델을 만들어 낸다면 병렬 말뭉치 자동생성해 대용량 말뭉치 구성에도 기여를 할 수 있는 무엇인가를 만들 수 있지 않을까..?
버트에 레이블을 정보를 추가하여 학습할 수 있다는 것을 알게됐고 가변 길이를 생성할 수 있도록 하는 것을 좀더 연구해 보면 어떨까 라는 생각을 하게된 논문.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰 #6] 문장 수준 관계 추출을 위한 개체 중심 구문 트리 기반 모델 (1) | 2023.05.15 |
|---|---|
| [논문 리뷰 #5] 한국어 오픈 도메인 대화 모델의 CTRL을 활용한 혐오 표현 생성 완화 (1) | 2023.05.14 |
| [논문 리뷰 #4] Attention Mechanism에 따른 포인터 네트워크 기반 의존 구문 분석 모델 비교 (0) | 2023.05.13 |
| [논문 리뷰 #3] 긴 문서를 위한 BERT 기반의 End-to-End 한국어 상호참조 해결 (1) | 2023.05.12 |
| [논문 리뷰 #1] FastText와 Bert를 이용한 자동 용어추출 (0) | 2021.11.30 |




댓글