문장 수준 관계 추출을 위한 개체 중심 구문 트리 기반 모델: 박성식, 김학수(건국대학교 컴퓨터공학과)
(제 33회 한글 및 한국어 정보처리 학술대회 논문집(2021년))

00. 서론
구문 트리의 구조적 정보는 문장 수준 관계 추출을 수행하는데 매우 중요한 자질 중 하나다. 기존 관계 추출 연구는 구문 트리에서 최단 의존 경로를 적용하는 방식으로 관계 추출에 필요한 정보를 추출하여 활용했다. 그러나 이런 트리 가지치기 기반의 정보 추출은 관계 추출에 필요한 어휘 정보를 소실할 수도 있다는 문제점이 존재한다. 이 논문은 개체 중심으로 구문 트리를 재구축 하고 모든 노드의 정보를 관계 추출에 활용하는 모델을 제안하여 문제점을 해소하고자 한다.
01. 관계추출

관계 추출이란 문장이나 문서 같은 비정형 데이터에 존재하는 개체들 간의 의미적 관계를 찾아내는 것이 목적이다. 문장 수준의 관계 추출은 한 문장과 문장에 존재하는 두 개체의 정보가 주어지면 그 두 개체 사이의 관계를 분류하는 문제로 볼 수 있다. 예시 문장은 "이건희"와 "이재용" 두 개체가 존재한다. 문맥을 보았을 때 두 개체간의 관계가 "parents:PER"임을 유추할 수 있다.
구문 정보는 문장 수준 관계 추출에 있어서 중요한 자질 중 하나이다. 의존 구문 트리에서 두 개체 사이의 최단 의존 경로(shortest dependency path, SDP)나 최소 공통 분모(lowest common ancester, LCA)노드를 사용하면 문장의 노이즈를 제거하면서 관계 추출에 필요한 정보를 습득 할 수 있다. 예시에서 보여주는 개체 사이의 의존 최단거리는 ("이재용은" -> "아들" -> "이건희의")이며, 이 정보만으로 충분히 관계를 유추할 수 있다. 그러나 최단 의존 거리처럼 트리를 가지치기(pruning)하는 것은 오히려 관계 추출의 필요한 문맥 정보를 소실하는 결과가 나타날 수 있다.

구문 정보만 사용 했을 때 중요한 문맥정보가 소실 되는 경우를 보여주는 예시이다. "자신의 아들"이라는 문맥을 참조했을 때 "샤를"과 "로타르 2세"의 관계가 parents임을 알 수 있다. 하지만 의존 구문 분석을 수행하고 의존 최단 경로의 정보만 사용했을때 "자신의 아들"이라는 중요한 문맥정보가 소실된다. 이로써 의존 최단 경로의 사용이 관계 추출에 부정적인 영향을 끼칠 수도 있다는 것을 확인 할 수 있다.
02. 관련 연구

관계 추출에 구문 정보를 적극적으로 활용하기 위한 연구는 다양하게 존재한다.
1. 구문 최단 경로 이용
구문 최단 경로를 통해 관계 추출에 불필요한 노이즈를 줄이고 필요한 정보만을 활용하는 방법이다. 하지만 최단 경로만 사용하면 관계 추출에 필요한 문맥 정보가 소실 되는 문제가 발생한다.
2. 최소 공통 부모를 중심으로 가지치기
문맥 정보의 소실을 완화하기 위해 두 개체 사이의 최소 공통 부모를 중심으로 가지치기를 수행한 서브 트리를 GCN(Graph Convolutional Networks)을 통해 인코딩 하는 방법으로 관계 추출을 수행하는 방법이다. 이 방법 또한 가지치기를 하는 과정에서 필요한 문맥 정보가 손실 될 수 있다.
3. Soft-pruning
구문 트리에 셀프 어텐션(self-attention)적용한 방법으로 문맥 정보 소실을 완화한다. 전체 구문 트리를 입력으로 받아 어텐션 가중치를 기반으로 중요 노드 사이의 연결은 강해지고 그 외의 연결은 약해지도록 학습을 진행한다. 이 방법은 구문 트리의 정보 반영을 어텐션 기법에 의존하기 때문에 주요 구문 정보가 희석될 가능성이 존재한다.
4. 사전 학습 언어 모델
대용량 말뭉치로 자가 지도 학습을 진행한 사전 학습 언어 모델을 관계 추출에 이용하는 방법이다. 사전 학습 언어 모델의 활용만으로도 기존 관계 추출 모델들을 뛰어넘는 성능을 보였으며, 사전 학습 언어 모델에서 개체를 표현하는 방법에 따라 더 높은 성능을 보일 수 있다.
03. 제안 모델

구조적 정보를 사용하면서 중요한 정보를 소실하지 않기 위해 의존 구문 트리를 개체 중심으로 재구성하는 방법을 사용하여 제안한다. 문장에 등장하는 개체를 트리의 root노드로 간주하고, 본래 의존 구문 트리의 정보를 기반으로 다른 노드와의 구문 관계 및 연결을 재구성하여 만든다. 재구성 한 트리의 구문 관계는 구문 거리로 대체된다. 재구성하여 만들어진 개체 중심 의존 트리는 GAT(Graph Attention network)에 입력해 개체 중심의 문맥 정보를 추출하게 된다. 구문 거리는 임의로 초기화된 벡터로 임베딩을 수행하고, 셀프 어텐션을 통해 중요한 위치가 강조된 분포를 출력한다. 개체와 구문적으로 가까운 거리에 위치한 단어들은 관계 추출에 필요한 정보를 내포하고 있을 가능성이 높으며, 이를 통해 구문적 정보를 얻을 수 있다.
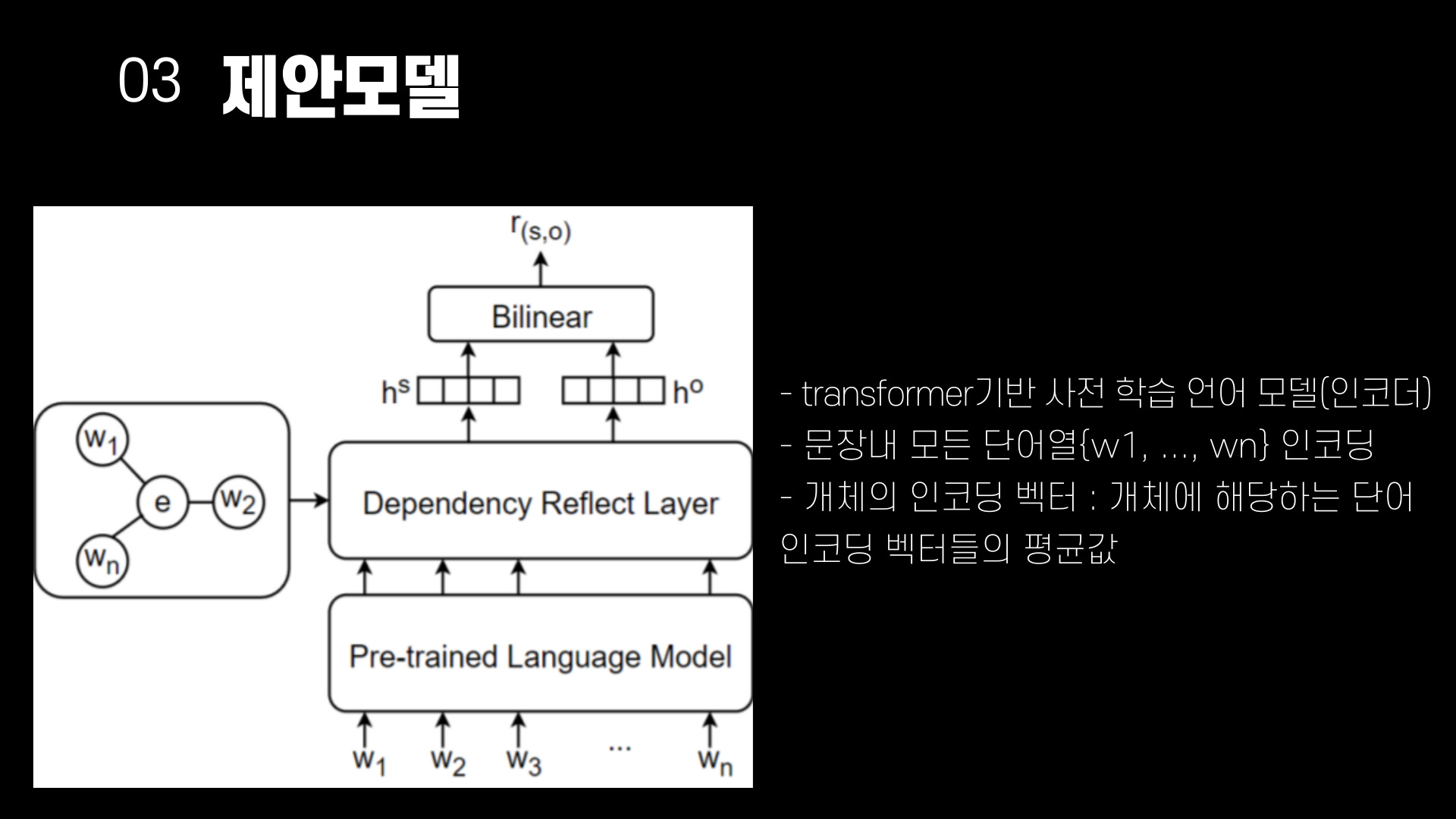
최근 대부분의 자연어처리 연구에서는 트랜스포머 기반 사전 학습 언어 모델을 사용해 주어진 문장이나 문서에서 문맥적 표현을 추출한다. 제안 모델은 트렌스포머 기반 사전 학습 언어 모델을 인코더로 사용해 문장 내 모든 단어열 {$w_1, w_2, ..., w_n$}의 인코딩을 진행한다. 문장 인코딩 후, 개체에 해당하는 단어 인코딩 벡터들의 평균 값으로 개체의 인코딩 벡터를 표현한다.

$c^e$는 개체 $e$의 인코딩 벡터를 의미하며, $k,l$은 개체의 시작 위치와 끝 위치를 나타낸다. $c_i$는 $i$번째 단어 $w_i$의 인코딩 벡터이다. 개체 인코딩 벡터 $c^e$와 모든 단어 인코딩 벡터 {$c_1, c_2, ..., c_n$}는 개체 중심 의존 트리의 구조 정보와 함께 의존 정보 반영계층에 입력된다.

관계 추출에 주어지는 개체는 subject, obfect 두 가지이므로, 구문 트리도 subject 중심트리, object 중심 트리 두 가지가 입력된다. 의존 정보 반영 계층에서는 두가지 방법으로 구문 의존 정보와 문맥 정보를 습득한다.
1. 개체의 문장 사이의 구조적 정보 취합을 위한 GAT계층
GAT에서는 트리 구조 정보를 바탕으로 개체 노드와 연결된 모든 단어 노드 사이의 연관 정보를 어텐션 기법을 통해 계산한다. $g^e$는 GAT를 통해 습득한 개체 노드와 이웃 노드 사이의 연관 정보가 반영된 값이다. GAT에서는 개체 인코딩과 단어 노드 사이의 bilinear attention을 통해 어텐션 점수 $s^e$를 계산하고, 이를 통해 연관도가 반영된 확률 분포 $\alpha^e$를 구한다. $W_\alpha$는 bilinear attention의 학습 가능한 파라미터 이며, $d$는 어텐션 스코어를 정규화 하기 위한 값으로, 개체 인코딩 벡터의 차원 크기를 의미한다.
개체 중심 의존 트리에서 개체 노드는 모든 단어 노드와 연결된 형태를 보이므로(root노드이기 때문) 관계 추출에 필요한 개체와 단어 사이의 문맥 정보를 학습을 통해 습득하게 된다.

2. 의존 거리 반영 계층
개체와 단어 사이의 의존 거리를 사용하여 구문 정보를 습득한다. 각 개체와 단어 사이의 의존 정보 점수 $s^e_i$는 마지막 수식과 같이 구해진다. $W_\beta$는 의존 정보 학습을 위한 파라미터이며, $b_\beta$는 편향값이다. $z_(e,z)$는 개체와 $i$번째 단어 사이의 구문 거리를 임베딩한 벡터이며 $\sigma$는 활성함수를 나타낸다. 단어 사이의 구문 거리의 임베딩인 $z_(e,z)$가 하나의 선형층을 통과한 후 활성함수를 통과한 값으로 이해하면 쉽다. 각 개체의 관점에서 구문적으로 중요한 단어의 확률분포를 softmax를 이용해 구하고, 두번째 수식을 통해 두 개체의 확률 분포를 융합한다. 이를 통해 두 개체 사이의 구문 정보를 습득하게 된다.

의존 정보 반영 계층 이후에 개체 인코딩, GAT 계층 결과 값, 의존 거리 반영 계층 결과 값을 연결하여 FFNN(feed-forward neural network)에 입력하여 최종 개체 인코딩 벡터를 구한다. 각 개체의 인코딩 벡터는 bilinear연산을 통해 두 개체의 의미적 관계를 예측하는데 사용된다.
04. 실험 결과

제안 모델의 평가를 위한 데이터는 영어 문장 수준 관계 추출 말뭉치인 TACRED와 한국어 말뭉치인 KLUE-RE를 사용한다. TACRED는 사람이 직접 검수하여 구축한 지도학습 관계 추출 데이터이며, no_relation을 포함해 42 종류의 관계 타입이 존재하며, 개체 타입은 16종류를 가진다. 의존 구문 트리가 함께 제공되기 때문에 이를 사용해 개체 중심 의존 구문 트리를 구축한다. KLUE-RE는 30개의 관계타입이 존재하며 개체 타입은 6종류를 가진다. 자체 개발한 의존 구문 분석 모델을 사용해 의존 구문 분석을 수행한다.
문장 임베딩을 위한 사전 학습 언어 모델은 RoBERTa-large 모델을 이용한다. 개체 중심 의존 트리를 제작할 때 구문 거리의 최대 값은 6으로 설정하고, 이를 넘는 구문 거리를 가질 경우 'inf'라는 special label을 할당한다.

기존 연구와 성능을 비교하기 위해 TACRED를 사용한 실험을 진행한다. +기호가 있는 연구는 외부 지식이나 추가 학습데이터를 사용한 연구들이다. 논문이 제안한 모델은 추가 데이터를 사용하지 않고도 높은 성능을 보였다. 제안 모델과 같이 구문 정보를 활용한 GCN, AGGCN과 비교했을 때 높은 성능을 보이는 이유는 사전 학습 언어 모델을 사용했기 때문으로 유추한다. 따라서 기존 구문 정보 활용 방법과 비교를 위해 GCN을 재구현 하여 같은 언어 모델을 기준으로 성능을 비교한다.

실험 결과 개체 중심 의존 트릴르 사용한 제안 모델이 같은 언어 모델을 사용한 GCN과 비교해도 더 높은 성능을 보이는 것을 알 수 있다.
표 3은 한국어 관계 추출 데이터를 이용한 실험 결과이다. 기준 모델인 KLUE-RoBERTa base/large 모델은 CLS벡터(문장의 전체적인 정보를 가짐)를 사용해 관계 추출을 진행했다. 역시 성능이 가장 높으나 영어 데이터에 비해 낮은 성능향상을 보이고 있다.

제안 모델이 보인 오답들을 분석한 예시를 보여준 표다. 오답 문장 중 100개 문장을 임의 추출하여 진행한다. 분석 결과, 절반 정도인 49개 문장에서 잘못 태깅되거나 모호한 경우가 존재했다. 첫 번째 문장에서 '인어공주'와 '에리얼'의 관계를 모델이 예측한 정답은 'alternate name'이지만 문장을 보았을때 틀렸다고 보기 어렵다. 두 번째 문장의 문맥을 보면 '유투브'는 생산물 보다는 플랫폼이 적당한 것 처럼 보이지만 정답으로 'product'가 태깅되어 있다. 이는 개체의 모호성으로 인해 잘못 태깅된 경우로 볼 수 있다. 마지막 문장에서는 문맥으로 보았을 때 '주인공'에 해당하는 개체는 '히나사키 미쿠'지만 '레이'에 'title'이 태깅되어 있다.
오류를 분석한 결과 데이터의 모호성이나 잘못 태깅된 경우가 해결 된다면 제안 모델의 성능이 더 높아질 것으로 기대된다.
05. 끝
문장 수준의 관계 추출에서 구조적 정보를 이용하면서 문맥 정보를 잃지 않고 이용하는 방법을 제시하는 논문이다. 의존 구문 분석 그래프를 개체 중심 그래프로 재구성하여 그래프 네트워크를 사용했다는 점에서 빛나는 아이디어라고 생각한다. 그래프 네트워크를 이용하기 위해 무엇을 이용하여 그래프를 구성하는 지가 중요한데 구조적으로도 의미적으로도 유의미한 정보를 이용가능하도록 그래프를 제시한것 같다.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰 #7] 자연어 생성 모델을 이용한 준지도 학습 기반 한국어 사실 확인 자료 구축 (0) | 2023.06.17 |
|---|---|
| [논문 리뷰 #5] 한국어 오픈 도메인 대화 모델의 CTRL을 활용한 혐오 표현 생성 완화 (1) | 2023.05.14 |
| [논문 리뷰 #4] Attention Mechanism에 따른 포인터 네트워크 기반 의존 구문 분석 모델 비교 (0) | 2023.05.13 |
| [논문 리뷰 #3] 긴 문서를 위한 BERT 기반의 End-to-End 한국어 상호참조 해결 (1) | 2023.05.12 |
| [논문 리뷰 #2] 마스크 언어 모델 기반 비병렬 한국어 텍스트 스타일 변환 (0) | 2022.03.11 |




댓글